pythonの基礎を勉強したので、そのまとめ
更新日:2019年2月24日
pythonの公式ページには、チュートリアルが存在します。そこにかいてあることを一通り手を動かしてやってみただけの内容です。対象とするバージョンは3系です。2系は考慮しません。
→ https://docs.python.org/ja/3/tutorial/index.html
環境の準備
いくつかの手段がありますが、私は
・anacondaを使って、pythonをインストール
・コーディングや実行はEclipseで行う
といったスタイルです。
anacondaはpythonやpython用のライブラリのインストールなどを自動で行ってくれる便利ツールです。
そしてpython環境を複数作って、それを管理してくれます(仮想環境と呼ばれているっぽい)。
anacondaを以下からインストールします。
インストール後、アプリを起動してみれば、まぁ、なんとなくわかると思います(たぶん)
→ https://www.anaconda.com/distribution/
とりあえず、仮想環境を1つ作っておきます(作らなくてもいいけど、今後のことも考えて、とりあえず作る・・・w)。
eclipseは、eclipse本体をDLし、それにpyDevというプラグインをいれて、使います(ほかの方法もあるはず)。
pyDevプラグインのインストールは、メニューから「ヘルプ」→「新規ソフトウェアのインストール」とたどり、以下のURLを追加して、pyDevプラグインをインストールします。
→ http://pydev.org/updates
pyDevをインストール後、pythonの環境のパスを入力します(以下の画像参照)
anacondaのインストールディレクトリ(私の環境では「E:\bin\Anaconda3」)の中に「envs」ディレクトリがあります。
その中にanacondaで作成したpythonの仮想環境名のディレクトリがあるはず(私の環境では「env1」というのを作った)。
そのディレクトリの中にある「python.exe」を、eclipseのpyDevの設定に、環境として設定してあげます。
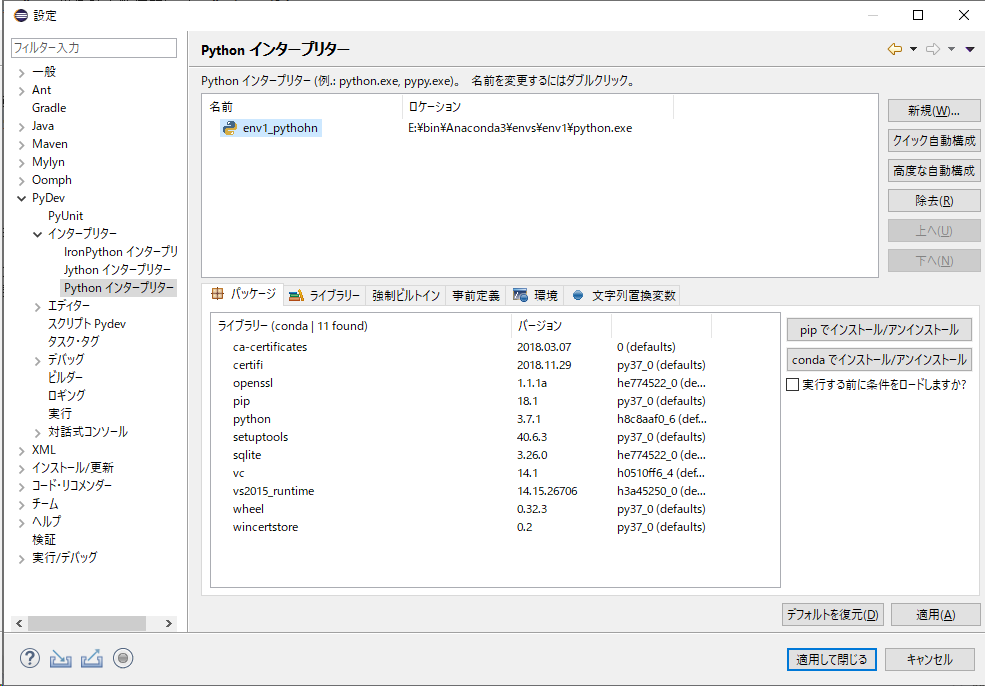
これで、準備完了・・・のはず。
(環境を作ってから、結構時間がたってから作ったので、過不足あるかも)
制御構文
基本的な構文です。
ほかの言語と基本的に変わりありません。
ただ、pythonの基本思想である{}によるパースをやめて、その代わりインデントを使う・・・という点は多少の慣れが必要です。
# サンプルで使用する定数たち
NEW_RENT_AMOUNT = 143000 #あたらしい家の家賃
PASSWORD = "GO is GOD" #合言葉
# コメント分
# 1行コメントアウトする場合は「#」を使用する
"""
複数行コメントアウトしたい場合は「"」か「'」を3つ連ねて、で囲む
囲まれたところはコメントとして扱われる。
"""
'''
こっちもOK
'''
# 変数の定義と型について
"""
型は自動判別。
変数の定義は特にない。定数は大文字にするのが通例らしい。
"""
# if文
"""
switch-case文の代わりにpythonではif-elif-elseを使うことになっている(らしい)
"""
print("■if文のサンプル")
currentRentAmount = 810 # 今の家賃
if currentRentAmount < 114514:
print("if文だけのサンプルです。\n高い・・・高くない?")
if currentRentAmount > NEW_RENT_AMOUNT:
print("今の家賃より安い。はっきしわかんだね。")
elif currentRentAmount == NEW_RENT_AMOUNT:
print("(今の家賃と違いが)ないです。")
elif currentRentAmount <= NEW_RENT_AMOUNT:
print("ぼったくりやろこれ!")
else:
print("例が悪かった。まぁ、else分も書けます")
# for文
print("■for文のサンプル")
"""
pythonのfor文は、リストなどのデータ型に対する反復処理をするためのもの・・・という考え方をしている。
for(int i=0;i<10;i++)といったことを実現するためには、「10回繰り返しのサンプル」のようにする。
range()が返すオブジェクトは、リスト・・・のような振る舞いをするが、リストではなく、イテラブル(iterable)というもの。
(実際にリストを作りにはlist(range(10))とする)
"""
#10回繰り返す
print("10回繰り返しのサンプル")
for i in range(10):
print("i : ", i)
# 配列を作成
characterArray = ["野獣先輩", "三浦", "木村"]
# 配列に対し、全件走査を行う
print("配列のデータに対し、全件走査を行うサンプル")
for characterName in characterArray:
print("name : " + characterName + "\tlen:", len(characterName))
# 上記と同じだが、今、自分が何番目のデータを見てるのか知りたい場合は、以下のような書き方で可能
print("配列のデータに対し、全件走査を行うサンプル(添え字を使ったアクセス)")
for i in range(len(characterArray)):
print("name : " + characterArray[i] + "\tlen:", len(characterArray[i]))
# そして、これではかっこ悪いので、いい感じにする方法が、以下の記載方法(関数を使う)
print("配列のデータに対し、全件走査を行うサンプル(添え字を使ったアクセス・・・の改良版)")
for i, v in enumerate(characterArray):
print(i,">>name : " + v + "\tlen:", len(v))
# さらには、複数の配列に対し、同時にループすることもできる
print("複数の配列のデータに対し、同時に処理することもできる")
characterNameArray = ["先輩", "MUR", "KMR"]
characterName2Array = ["foo↑", "ゾ", "イケメン"]
for a,b,c in zip(characterArray, characterNameArray, characterName2Array):
print("name : {0}, opt1:{1}, opt2:{2}".format(a,b,c))
# break/continueについて
print("■break/continueについて")
"""
特に意味のないサンプルだが、他の言語と使い方は同じ
"""
for i in range(10):
print("i loop:",i)
for j in range(10):
if (i+j) % 2:
continue;
print("loop = i:{0}, j:{1}".format(i,j));
# 5回目以降は実行しないようにループを抜ける
if j >= 5 :
break;
# for文のelseについて
print("■for文のelseについて")
"""
forにelse句を付けることが可能。
ループが終わったら、最後にelse句の処理を実行します。
ただし、breakでループを抜けた場合は実行しません。
例外処理に使うtry句にもelseを付けることができ、for文にもelseを付けることができ、正常に処理が終わったら実行するコード
の記載を、構文レベルでサポートしているのがpythonの特徴。
"""
for i in range(3):
print("loop count : {0}".format(i))
else:
print("ループが終わったゾ") # ループが終わった時に実行される。
for i in range(3):
print("loop count : {0}".format(i))
break;
else:
print("ループが終わったゾ") # ループがbreakで途中で終わるため、この部分は実行されない。
# while文について
print("■while文もあるよ")
whileCounter = 0
while whileCounter < 5:
print("while loop:",whileCounter)
whileCounter +=1;
else:
print("すべてのwhileループをやりきりました") # else句もオプションで付けることが可能
# pass文
print("■pass文")
"""
文法上記載が必要なケースであるが、記載することが無いときに、使う。
または、関数などの記載の途中だが、とりあえずなにか書いておくときに使う。
以下のコードで無限ループになる。ループ処理の中になにも書くことがないとき、pass文を記載しておく
while True:
pass
"""
pass
"""
実行結果は、以下の通りです(出力されるもの)。
■if文のサンプル
if文だけのサンプルです。
高い・・・高くない?
ぼったくりやろこれ!
■for文のサンプル
10回繰り返しのサンプル
i : 0
i : 1
i : 2
i : 3
i : 4
i : 5
i : 6
i : 7
i : 8
i : 9
配列のデータに対し、全件走査を行うサンプル
name : 野獣先輩 len: 4
name : 三浦 len: 2
name : 木村 len: 2
配列のデータに対し、全件走査を行うサンプル(添え字を使ったアクセス)
name : 野獣先輩 len: 4
name : 三浦 len: 2
name : 木村 len: 2
配列のデータに対し、全件走査を行うサンプル(添え字を使ったアクセス・・・の改良版)
0 >>name : 野獣先輩 len: 4
1 >>name : 三浦 len: 2
2 >>name : 木村 len: 2
複数の配列のデータに対し、同時に処理することもできる
name : 野獣先輩, opt1:先輩, opt2:foo↑
name : 三浦, opt1:MUR, opt2:ゾ
name : 木村, opt1:KMR, opt2:イケメン
■break/continueについて
i loop: 0
loop = i:0, j:0
loop = i:0, j:2
loop = i:0, j:4
loop = i:0, j:6
i loop: 1
loop = i:1, j:1
loop = i:1, j:3
loop = i:1, j:5
i loop: 2
loop = i:2, j:0
loop = i:2, j:2
loop = i:2, j:4
loop = i:2, j:6
i loop: 3
loop = i:3, j:1
loop = i:3, j:3
loop = i:3, j:5
i loop: 4
loop = i:4, j:0
loop = i:4, j:2
loop = i:4, j:4
loop = i:4, j:6
i loop: 5
loop = i:5, j:1
loop = i:5, j:3
loop = i:5, j:5
i loop: 6
loop = i:6, j:0
loop = i:6, j:2
loop = i:6, j:4
loop = i:6, j:6
i loop: 7
loop = i:7, j:1
loop = i:7, j:3
loop = i:7, j:5
i loop: 8
loop = i:8, j:0
loop = i:8, j:2
loop = i:8, j:4
loop = i:8, j:6
i loop: 9
loop = i:9, j:1
loop = i:9, j:3
loop = i:9, j:5
■for文のelseについて
loop count : 0
loop count : 1
loop count : 2
ループが終わったゾ
loop count : 0
■while文もあるよ
while loop: 0
while loop: 1
while loop: 2
while loop: 3
while loop: 4
すべてのwhileループをやりきりました
■pass文
"""
関数・ラムダ式
関数の定義や、呼び出し方のサンプルです。
ラムダ式についても、ちょっとサンプルを書きました。
#関数について
print("■関数について")
"""
あまり注意する点はありません。引数は値渡しになります。
デフォルト引数を指定できますが、これについては省略します(これで良いことがあった試しがないため)
"""
# 関数を定義する
def sampleFunc1(arg):
"""
サンプルの関数です.
1行目に概要を記載し、詳細は2行目はブランクにし、3行目以降に記載します。
1行目の末尾は「.」で終わる必要があります。
これは、「ドキュメンテーション文字列」といわれるもので、関数に対するコメントの記載方法となっております。
省略も可能です。
また、2行目以降を省略し、1行目だけ記載するでもOKです。
「ドキュメンテーション文字列」そのものを省略することも可能ですが、非推奨・・・かと思います。
"""
if arg > 0:
return sampleFunc1(arg-1) + arg
else:
return 0
def sampleFunc2(*args):
"""可変引数のサンプル"""
for i,v in enumerate(args):
print("sampleFunc2 可変引数 = {0} : {1}".format(i, v))
def sampleFunc3(*args, **argMap):
"""引数に連想配列的なものを渡すことが可能。可変引数とセットで使う場合は、上記のような引数の並び順にする必要あり."""
for i,v in enumerate(args):
print("sampleFunc3 args 可変引数 = {0} : {1}".format(i, v))
for keyMap in argMap:
print("sampleFunc3 argMap {0} => {1}".format(keyMap, argMap[keyMap]))
def sampleFunc4(name, value):
""" 引数リストのアンパックについて.
引数に値を指定する際、こういう使い方もできる・・・という話の例です(呼び出し元を参照)。
"""
print("name : ", name)
print("value : ", value)
# 関数を呼び出す
sampleFuncResult = sampleFunc1(10);
print("sampleFunc result : ", sampleFuncResult)
#sampleFunc2(可変引数の関数)を呼び出す
sampleFunc2("あいうえお",100,"かきくけこ",1000,"さしすせそ")
#sampleFunc3(可変引数と、マップを引数に指定する)を呼び出す
sampleFunc3("あ","い", bukatu="迫真空手部", sensei="AKYS", tiratira="見ていない")
#sampleFunc4を呼び出す(※2つの引数を受け取る関数が、引数に「*」をつけると、1番目の要素が第1引数、2番目の要素が第2引数に使われる)
sampleFunc4ArgsArray = ["先輩", "24歳学生です"]
sampleFunc4(*sampleFunc4ArgsArray)
#sampleFunc4を呼び出す(※2つの引数を受け取る関数が、引数に「**」をつけると、引数のmapで指定したkeyが引数の名前に対応したものにセットされる)
sampleFunc4ArgsMap = {"name": "先輩",
"value" : "24歳学生です"}
sampleFunc4(**sampleFunc4ArgsMap)
#ラムダ式について
print("ラムダ式について")
"""
ラムダ式は、無名の関数を生成します。
引数の型に、関数オブジェクトを使うところには、ラムダ式も使うことが可能。
ラムダ式は、関数定義と同じで、スガーシンタックス的な扱い・・・らしい。
"""
f = lambda x :x*10
print("ラムダ式f result : ", f(10))
"""
実行結果は以下の通りです。
■関数について
sampleFunc result : 55
sampleFunc2 可変引数 = 0 : あいうえお
sampleFunc2 可変引数 = 1 : 100
sampleFunc2 可変引数 = 2 : かきくけこ
sampleFunc2 可変引数 = 3 : 1000
sampleFunc2 可変引数 = 4 : さしすせそ
sampleFunc3 args 可変引数 = 0 : あ
sampleFunc3 args 可変引数 = 1 : い
sampleFunc3 argMap bukatu => 迫真空手部
sampleFunc3 argMap sensei => AKYS
sampleFunc3 argMap tiratira => 見ていない
name : 先輩
value : 24歳学生です
name : 先輩
value : 24歳学生です
ラムダ式について
ラムダ式f result : 100
"""
リスト・リスト内包表記・タプル・集合型・辞書型
リストは、よくあるあのリストです。
リスト内包表記はリスト型に対するループ処理を1行で書けるよ・・・!的なやつです。
タプルは一度セットすると変更できないリストのようなものです(たぶん)。
集合型は、あの集合論のやつです。
辞書型は、連想配列のことですね。
print("■リストについて")
# 空のリストを作成と同時に要素のセットも可能
defaultList = ["お湯ください", "休憩中よ", "ぷはー"]
# 空のリストを定義
valueList = []
#appendでリストの後ろに要素を追加する
valueList.append("あいうえお")
valueList.append("かきくけこ")
valueList.append("さしすせそ")
#indexを指定して要素の追加も可能(以下は要素の最後のindexを指定して追加)
valueList.insert(len(valueList), "たちつてと")
#listにlistを追加することも可能(appendを使ってListを追加すると、List型が1要素として追加されることになってしまう)
valueList.extend(defaultList)
#引数で指定した値と同じ要素を、リストの先頭から検索し、最初に見つかったものを削除する(見つからない場合ValueError例外が投げられる)
try:
valueList.remove("あいうえお")
except ValueError:
print("valueList.remove : valueListに「あいうえお」はありませんでした")
#引数で指定した同じ値を探す(見つからない場合ValueError例外が投げられる)
#第2引数で指定した位置から、第3引数で指定した位置の範囲で検索する。省略すると、全範囲を検索する
try:
valueList.index("あいうえお", 0, len(valueList))
except ValueError:
print("valueList.index : valueListに「あいうえお」はありませんでした")
#指定した値の出現回数を取得する
occurrenceAmount = valueList.count("ぷはー")
#リストのコピー(shallowCopy)もできる。以下2通りの書き方ができる
copyList1 = valueList.copy()
copyList2 = valueList[:]
#リストの全件クリア
valueList.clear()
# リスト内包表記
print("■リスト内包表記について")
"""
以下のforループが終わった後、iの変数はスコープ外となって、消えてなくなると思いきや、iは値9がセットされて、存在しつづけたままです。
(・・・なんでC言語の病気をわざわざ残したのだろうか。。。)
それをなくすよう、別の書き方ができるよ・・・というのが「リスト内包表記」・・・らしい。
"""
sampleList1 = []
for i in range(10):
sampleList1.append(i*10)
#上記処理は、以下のように書き換え可能(どちらも同じ結果となる)
sampleList2 = list(map(lambda x:x*10, range(10)))
sampleList3 = [x*10 for x in range(10)]
#リスト内砲表記に条件句を加えることも可能
sampleListList1 = [(x, y) for x in range(10) for y in range(10) if x==y]
# 上記処理は、以下の処理を1行で記載したのと同じ
sampleListList2 = []
for x in range(10):
for y in range(10):
if x==y:
sampleListList2.append((x, y))
#リストを使ってこんなこともできる例(以下のマトリクスの行・列の入れ替えをおこなったデータを作成する)
matrix = [
[1, 2, 3, 4, 5],
[6, 7, 8, 9, 10],
[11, 12, 13, 14, 15]
]
#以下の2つはほぼ同じ結果となる(リストになるかタプルになるか違いがあるが・・・あまり影響はない)。
#リスト内砲表記を使っても行列入れ替えは実現できるが、関数を使た方が簡単に実現できる)
newMatrix1 = [[row[i] for row in matrix] for i in range(5)]
newMatrix2 = list(zip(*matrix))
# リストから要素を削除する
print("■リストから要素を削除する")
delSampleList = ["あいうえお", "かきくけこ", "さしすせそ"]
# indexを指定して削除する
del delSampleList[1]
# リストの要素全体を削除する
del delSampleList
#タプルとシーケンス
print("■タプルについて")
"""
pythonにはシーケンスデータ型として、list, tuple, rangeの3つがある。listとrangeは今までの例に出てきた。
タプルは、コンマで区切られたいくつかの値を保持し、1度作ると編集不可なデータです。
変更不可の定数定義に使ったりするらしい(pythonにはC言語のconstやjavaのfinalにあたるものがないっぽい)
以下に例を示す。
"""
sampleTuple1 = 1,2,"あいうえお"
sampleTuple2 = 3,"かきくけこ", (10, 20, "さしすせそ") # タプルはネストも可
#0個、1個のタプルは以下の記載で作成できる
sampleTupleBlank = () # 要素が0個のタプル
sampleTupleOne = 10, # 要素が1個のタプル
#ネストできても、いろんな型を混ぜると、以下のように型判定が必要になったりするので、使い方は考えること
for tupleValue in sampleTuple2:
if type(tupleValue) is str:
print("文字列 tupleValue:", tupleValue)
if type(tupleValue) is int:
print("数値tupleValue:", tupleValue)
if type(tupleValue) is tuple:
for taplueValue2 in tupleValue:
print("taplueValue2:", taplueValue2)
#また添え字を使ったアクセスも可能
print("sampleTuple2 length: ", len(sampleTuple2))
print("sampleTuple2[0] : ", sampleTuple2[0])
print("sampleTuple2[0:2] : ", sampleTuple2[0:2])
print("sampleTuple2[0:2] type : ", type(sampleTuple2[0:2]))
# 集合型
print("■集合型について")
"""
以下のように、set関数にabcdef・・・などの文字列を渡しているが、set型(重複のないリスト)として、「a」「b」「c」「d」「e」「f」の6個の
要素を持ったset型オブジェクトが作られる。
これに対し、集合関数で演算ができる。
"""
setA = set("abcdef")
setB = set("efghij")
print("setA:", setA);
print("setB:", setB);
result1 = setA | setB
print("論理和 : ", result1)
result2 = setA & setB
print("論理積 : ", result2)
result3 = setA ^ setB
print("排他的論理和 : ", result3)
#辞書型
print("辞書型について")
"""
いわゆる連想配列です
"""
#連想配列を定義(初期値とセットで定義も可能
sampleMap = {"HP": 114514, "MP": 810, "MONEY":0}
#項目を追加(すでにある場合は値を更新する
sampleMap["HP"] = 1145141919
sampleMap["SP"] = 100
#要素を削除する
del sampleMap["MONEY"]
# keyの一覧を取得
sampleMapKeyList = list(sampleMap)
for mapKey in sampleMapKeyList:
print("key:{0} value:{1}".format(mapKey, sampleMap[mapKey]))
#dictコンストラクタを使って、キーと値のペアのタプルからマップを作ることもできます
sampleMap2 = dict([("HP", 364364), ("MP", 143000)])
"""
実行結果は以下の通り
■リストについて
valueList.index : valueListに「あいうえお」はありませんでした
■リスト内包表記について
■リストから要素を削除する
■タプルについて
数値tupleValue: 3
文字列 tupleValue: かきくけこ
taplueValue2: 10
taplueValue2: 20
taplueValue2: さしすせそ
sampleTuple2 length: 3
sampleTuple2[0] : 3
sampleTuple2[0:2] : (3, 'かきくけこ')
sampleTuple2[0:2] type : <class 'tuple'>
■集合型について
setA: {'b', 'e', 'a', 'f', 'c', 'd'}
setB: {'h', 'g', 'e', 'f', 'j', 'i'}
論理和 : {'h', 'b', 'g', 'e', 'a', 'f', 'j', 'c', 'd', 'i'}
論理積 : {'e', 'f'}
排他的論理和 : {'h', 'b', 'd', 'g', 'a', 'c', 'j', 'i'}
辞書型について
key:HP value:1145141919
key:MP value:810
key:SP value:100
"""
モジュールとdir関数
ほかのファイルに定義した関数などを、使うことができます(それをモジュールと言う・・・たぶんw)
別ファイルを使用するにはimportする必要があります。
ソースのコメントにも記載しましたが、サンプルでは、実行するpythonファイルと同じディレクトリ内に、「mod」というディレクトリを作成し、そこに「study4Module.py」ファイルを配置しています。
#-------------------------------------------------------------------
#このサンプルの前提として、以下のソースのファイルが、「mod」ディレクトリの中に「study4Module.py」というファイルで
#存在していることが前提です
""" study4Module.py
study4Message = "にんじんしりしり"
def getModuleName():
return __name__
"""
#-------------------------------------------------------------------
#モジュール
print("■モジュールについて")
"""
モジュールとしてファイル分割された場合、モジュールは独立したシンボルテーブルを持っている。
なので、モジュール内部のグローバル変数は、そのモジュール内部の中のグローバル変数・・・となる。
結果、モジュール内部のグローバル変数と、今実行しているスクリプトのグローバル変数が衝突することはない。
モジュール内部のグローバル変数へのアクセス方法も、以下の例に示す。
また、モジュールは、実行効率上の理由でpythonインタープリタの1セッションごとに1回だけimportされる。
実行中にスクリプトを変更した場合は、今の処理を止めて、再度実行する必要がある。
(一応、モジュールをリロードする処理もある(importlib.reload関数))
"""
#「mod」というディレクトリの下にstudy4Module.pyというファイルを読み込む
# 同じ階層になるならば「import study4Module」だけでOK。今回は、「mod」ディレクトリの中に「study4Module.py」を作り、それを読み込む例
from mod import study4Module
"""
ちなみに、以下のように、末尾に「 as 名前」とやると、study4Moduleから別の名前でアクセスできる
import study4Module as A
なので以下のようにメソッドを使うことになる。
moduleName = A.getModuleName()
さらには、
aiueo = study4Module
moduleName = aiueo.getModuleName()
なんて使い方もできる。
"""
#study4Moduleに定義した関数を呼び出す
moduleName = study4Module.getModuleName()
print("moduleName : ",moduleName)
#study4Moduleにあるグローバル変数にアクセスする
print("study4Moduleのstudy4Messageの値を参照:", study4Module.study4Message)
# dir関数について
print("■dir関数について")
"""
引数有りでdir関数を呼び出すと、指定したモジュールにどんなものが定義されているか(関数名や変数名など全部)をリストで返します。
引数なしの場合、現在定義されているものすべてが返ってきます。
"""
modItemList = dir(study4Module)
print("dir(study4Module):")
print(modItemList)
allitemList = dir();
print("dir():")
print(allitemList)
#組み込み関数や変数について
print("■組み込み関数や変数の一覧を取得する")
"""
一覧取得するだけです。こういうのが組み込みで定義されてるんだな・・・と思う程度の、参考レベルの話です。
"""
import builtins # import文は通例、スクリプトの文頭に記載するが、どこにでも記載できる
buildInItemList = dir(builtins)
#出力する大量に出てくるので、出力結果はここに記載しません・・・
print(buildInItemList)
"""
実行結果は、以下の通りです。
■モジュールについて
moduleName : mod.study4Module
study4Moduleのstudy4Messageの値を参照: にんじんしりしり
■dir関数について
dir(study4Module):
['__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'getModuleName', 'study4Message']
dir():
['__annotations__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'modItemList', 'moduleName', 'study4Module']
■組み込み関数や変数の一覧を取得する
['ArithmeticError', 'AssertionError', 'AttributeError', 'BaseException', 'BlockingIOError', 'BrokenPipeError', 'BufferError', 'BytesWarning', 'ChildProcessError', 'ConnectionAbortedError', 'ConnectionError', 'ConnectionRefusedError', 'ConnectionResetError', 'DeprecationWarning', 'EOFError', 'Ellipsis', 'EnvironmentError', 'Exception', 'False', 'FileExistsError', 'FileNotFoundError', 'FloatingPointError', 'FutureWarning', 'GeneratorExit', 'IOError', 'ImportError', 'ImportWarning', 'IndentationError', 'IndexError', 'InterruptedError', 'IsADirectoryError', 'KeyError', 'KeyboardInterrupt', 'LookupError', 'MemoryError', 'ModuleNotFoundError', 'NameError', 'None', 'NotADirectoryError', 'NotImplemented', 'NotImplementedError', 'OSError', 'OverflowError', 'PendingDeprecationWarning', 'PermissionError', 'ProcessLookupError', 'RecursionError', 'ReferenceError', 'ResourceWarning', 'RuntimeError', 'RuntimeWarning', 'StopAsyncIteration', 'StopIteration', 'SyntaxError', 'SyntaxWarning', 'SystemError', 'SystemExit', 'TabError', 'TimeoutError', 'True', 'TypeError', 'UnboundLocalError', 'UnicodeDecodeError', 'UnicodeEncodeError', 'UnicodeError', 'UnicodeTranslateError', 'UnicodeWarning', 'UserWarning', 'ValueError', 'Warning', 'WindowsError', 'ZeroDivisionError', '__build_class__', '__debug__', '__doc__', '__import__', '__loader__', '__name__', '__package__', '__spec__', 'abs', 'all', 'any', 'ascii', 'bin', 'bool', 'breakpoint', 'bytearray', 'bytes', 'callable', 'chr', 'classmethod', 'compile', 'complex', 'copyright', 'credits', 'delattr', 'dict', 'dir', 'divmod', 'enumerate', 'eval', 'exec', 'exit', 'filter', 'float', 'format', 'frozenset', 'getattr', 'globals', 'hasattr', 'hash', 'help', 'hex', 'id', 'input', 'int', 'isinstance', 'issubclass', 'iter', 'len', 'license', 'list', 'locals', 'map', 'max', 'memoryview', 'min', 'next', 'object', 'oct', 'open', 'ord', 'pow', 'print', 'property', 'quit', 'range', 'repr', 'reversed', 'round', 'set', 'setattr', 'slice', 'sorted', 'staticmethod', 'str', 'sum', 'super', 'tuple', 'type', 'vars', 'zip']
"""
パッケージ
パッケージの主な目的は、人への提供・・・という観点らしい。
なにかしらの機能を1つのパッケージにまとめておいて、みんなに使ってもらうようにする時の、まとまりを定義する。
モジュールとパッケージの違いは、パッケージの場合、そのディレクトリに「__init__.py」を用意する。
これはパッケージ全体の初期化処理を記載する特別なファイル、かつ、このファイルがディレクトリにあると、このディレクトリはパッケージであると認識される。
今回作成したのは、以下の6ファイル。
pakディレクトリの中に「__init__.py」を作成していますので、これで「pak」というパッケージを定義しています。
そして、さらに「msg」ディレクトリの中にも「__init__.py」ディレクトリを定義していますので、「msg」というパッケージを定義しています(pakの中にあるので、「pak.msg」というパッケージになる)

そして、実行するのは「study6.py」というファイルです。
以下に、各ファイルの中を示します。
実行結果は「study6.py」の中の下に、コメント文で入れておきました(今回、あまり出力結果は重要ではありませんが)
pak.__init__.py
print("pak.__init__.pyが呼び出されました")
# 公開するファイルをインポートする
from . import calc
#このパッケージを「import *」でインポートした場合に、読み込む対象を指定する(基本的に「import *」でのimportは行わない。javaと一緒。)
#なので記載しない
#__all__ = ["calc"]
pak.calc.py
# __init__.pyに記載されているものをimportしてくる(しかし、この方法では、名前空間が汚染される)
#「from pak.msg import *」と記載も可能だが、以下のように相対パスで指定することも可能
from . import msg
MATERIAL_ITEM_INDEX_IRON = 0
MATERIAL_ITEM_INDEX_TITAN = 1
# 引数a,bを計算して返す
def createMaterialWeightMessage(weight, materialType):
resultWeight = msg.materialWeight.getMaterialWeight(materialType) * weight
return msg.formatMessage.createMessageKg(resultWeight)
pak.msg.__init__.py
print("pack.msg.__init__.pyが呼び出されました")
# 公開するファイルをインポートする
from . import formatMessage
from . import materialWeight
#このパッケージを「import *」でインポートした場合に、読み込む対象を指定する(基本的に「import *」でのimportは行わない。javaと一緒。)
#なので記載しない
#__all__ = ["formatMessage", "materialWeight"]
pak.msg.formatMessage.py
def createMessageKg(num):
resultMessage = "重さは{0}キログラムですね。".format(num)
return resultMessage
pak.msg.materialWeight.py
SPECIFIC_GRAVITY_LIST = [7.85, 4.51]
# 指定されたアイテムの比重を返す(2以上のindexが指定された場合については考慮しないw
def getMaterialWeight(index):
return SPECIFIC_GRAVITY_LIST[index]
study6.py
#パッケージについて
print("■パッケージについて")
"""
ディレクトリは以下に「__init__.py」ファイルを作成すると、そのディレクトリはパッケージとなる。
__init__.pyはブランクのファイルでもいいが、パッケージの初期化処理を記載してもよい。
サンプルでは、パッケージをimportしたときに使いたいモジュールを、importする記載をしています
"""
import pak
showMessage = pak.calc.createMaterialWeightMessage(100, pak.calc.MATERIAL_ITEM_INDEX_TITAN)
print(showMessage)
"""
実行結果は、以下の通りです。
■パッケージについて
pak.__init__.pyが呼び出されました
pack.msg.__init__.pyが呼び出されました
重さは451.0キログラムですね。
"""
文字列の整形出力
文字列を整形して出力する簡単な方法があるよ・・・というサンプル。
# 文字列の整形出力について
print("■文字列の整形出力について")
"""
こんなことができるんだレベルの話です。デバッグ時のログ出力にでも使うぐらいかと。
"""
#「フォーマット済み文字リテラル」とは、先頭に「f」か「F」をつけて、文字列中に「{式}」を記載すると、pythonがうまいこと整形してくれる
import math
print(f'円周率 : {math.pi:.3f}')
valueList = {'HP':114514.0, 'MP':810.810, 'SP':0.143}
for k,v in valueList.items():
print(f'{k:5} : {v:10.5f}')
#また、値の変換もできる
#「!a」:ascii()で変換する (アスキーコード変換)
#「!s」:str()で変換する (人間の読める文字に変換)
#「!r」:repr()で変換する (pythonのコードに変換)
targetMsg = "ゆがみねぇな"
print(targetMsg, f" : {targetMsg!a}")
print(targetMsg, f" : {targetMsg!s}")
print(targetMsg, f" : {targetMsg!r}")
#format関数を使う
print("{0} : {1}".format("あいうえお", "かきくけこ"))
print("{0} : {1:5.5f} {comment}".format("数値", 114.514, comment="うひw"))
# formatにキーワード引数として渡す、以下のような使い方も可能
print("HP {HP:7.0f} MP {MP:5.5f} SP {SP:.6f}".format(**valueList))
#ゼロフィルもある
print("zero fill : ", '114514'.zfill(10))
"""
実行結果は以下となります。
■文字列の整形出力について
円周率 : 3.142
HP : 114514.00000
MP : 810.81000
SP : 0.14300
ゆがみねぇな : '\u3086\u304c\u307f\u306d\u3047\u306a'
ゆがみねぇな : ゆがみねぇな
ゆがみねぇな : 'ゆがみねぇな'
あいうえお : かきくけこ
数値 : 114.51400 うひw
HP 114514 MP 810.81000 SP 0.143000
zero fill : 0000114514
"""
ファイルの読み書き
ファイルの書き込み・読み込みのサンプルです。
また、jsonの読み書きのサンプルも、ソースの後半にあります。
#ファイルの読み書きについて
print("■ファイルの読み書きについて")
#このサンプルは、ファイルを出力して、また、そのファイルからデータを読み込みます。
#出力先パスは以下で設定します
DIRECTORY_PATH = "d:/"
FILE_NAME = "alctail_tmp114514.txt"
FILE_NAME_JSON = "alctail_tmp114514_jsonSample.json"
# ファイルの出力先パス
FILE_PATH = DIRECTORY_PATH + FILE_NAME
FILE_JSON_PATH = DIRECTORY_PATH + FILE_NAME_JSON
#ファイルを新規作成しデータを書き込む(第二引数はモードの指定。c言語のfopenとほぼ同じ)
with open(FILE_PATH, "w") as f:
f.write("abcdefg\n")
f.write("1145141919810\n")
f.write("あいうえお\n")
# 本当ならばfをcloseする処理を呼ぶ必要があるがwith句を使っているので「定義済みクリーンアップ処理」というものがあり自動でcloseされる(以降、f.closeはすべてコメントアウト)
#f.close()
#ファイルを読み込む(1行づつ読み込む)
with open(FILE_PATH, "r") as f:
while True:
readData = f.readline()
if not readData:
break
print("readData:", readData.strip()) #strip関数で末尾の関数を削除している
print("ファイルを読み終わりました!")
#f.close()
#ファイルをすべて読み込んで、改行でsplitした結果のリストを取得するには、以下の記載だけでいけます
readResultList = []
with open(FILE_PATH, "r") as f:
readResultList = f.readlines()
#f.close()
#jsonの読み書きについて
print("■jsonの読み書きについて")
import json
#jsonのデータを書き込む
jsonData = {
"title": "妖精哲学の三信について",
"author": "兄貴スレの人々",
"detail":{
"head1": "だらしねぇという 戒めの心",
"head2": "歪みねぇという 賛美の心",
"head3": "仕方ないという 許容の心"
},
"relation":["森の妖精", "妖精哲学", "カズヤの教え"]
}
#ファイルにjsonを保存する
with open(FILE_JSON_PATH, "w") as f:
json.dump(jsonData, f)
#f.close()
#ファイルに保存したjsonを読み込む
readJsonData = {}
try:
with open(FILE_JSON_PATH, "r") as f:
readJsonData = json.load(f)
f.close()
except json.JSONDecodeError as e:
print(e)
print("読み込んだjsonのデータ:", readJsonData)
"""
実行結果は、以下の通りです
■ファイルの読み書きについて
readData: abcdefg
readData: 1145141919810
readData: あいうえお
ファイルを読み終わりました!
■jsonの読み書きについて
読み込んだjsonのデータ: {'title': '妖精哲学の三信について', 'author': '兄貴スレの人々', 'detail': {'head1': 'だらしねぇという 戒めの心', 'head2': '歪みねぇという 賛美の心', 'head3': '仕方ないという 許容の心'}, 'relation': ['森の妖精', '妖精哲学', 'カズヤの教え']}
"""
例外処理
pythonには、例外処理もあります。
else句を書けるのか特徴ですかね。
#例外について
print("■例外処理について")
"""
組み込み型の例外については、以下を参照
https://docs.python.org/ja/3/library/exceptions.html#bltin-exceptions
ユーザー定義の例外を作成することも可能。
"""
#ユーザー定義の例外クラスを作成
class AlctailExceptionBase(Exception):
pass
class AlctailExceptionBaseAImpl(AlctailExceptionBase):
"""サンプル用の例外クラスA"""
def __init__(self, expression, message):
self.expression = expression
self.message = message
class AlctailExceptionBaseBImpl(AlctailExceptionBase):
"""サンプル用の例外クラスB"""
def __init__(self, expression, message):
self.expression = expression
self.message = message
#value1 = 10
#value2 = 0
try:
#0による除算で組み込みの例外を発生させる
#result = value1 / value2
#例外を投げる(exceptの記載の順番に注意。先に「AlctailExceptionBase」を記載すると、こちらでcatchされる)
raise AlctailExceptionBaseBImpl("aaaaaaaaaaa", "bbbbbbbb")
except AlctailExceptionBaseBImpl as e:
print("AlctailExceptionBaseBImpl:",e)
except AlctailExceptionBaseAImpl as e:
print("AlctailExceptionBaseAImpl:", e)
except AlctailExceptionBase as e:
print("AlctailExceptionBase", e)
except:
print("上記で記載した例外に当てはまらない場合、ここでどんな例外でもcatchします。")
else:
print("else句です。この句はオプションです。例外が発生しなかった場合実行されます。")
finally:
print("finally句です。この句はオプションです。この句は例外が発生してもしなくても常に実行されます。")
"""
実行結果は、以下の通りです。
■例外処理について
AlctailExceptionBaseBImpl: ('aaaaaaaaaaa', 'bbbbbbbb')
finally句です。この句はオプションです。この句は例外が発生してもしなくても常に実行されます。
"""
変数のスコープについて
今までのサンプルでは、てきとーにやってきましたが、変数スコープの概念がpythonにもちゃんとあります。
同じ名前の、グローバル変数など、外の世界の変数があった場合でも、特に指定しない限りは、ローカル変数のものを指す・・・というのが基本方針っぽいですね。
#スコープについて
print("■スコープについて")
"""
global文は、グローバル変数 にアクセスするように宣言する記載(たぶん)
nonlocal文は、1つ外のスコープの変数にアクセスするように宣言する記載(たぶん)
実行結果は、以下の通りとなる。
sampleMessage (1): func1でセット
global sampleMessage: オッハー
f1から見たsampleMessage: f1です!
sampleMessage (2): func1でセット
global sampleMessage: オッハー
f2から見たsampleMessage: f2です!
sampleMessage (3): f2です!
global sampleMessage: オッハー
f3から見たsampleMessage: f3です
sampleMessage (4): f2です!
func1実行終了: f3です
実行結果からわかるのは、自分のスコープ外に同じ名前のものがあっても、それを上書きしないということ。
globalやnonlocalを使ったときにはじめて、外のスコープの値に対し、影響を与えることができる・・・という風になっているようだ。
"""
sampleMessage = "オッハー"
def globalSampleMessageShow():
print("global sampleMessage:", sampleMessage)
def func1():
sampleMessage = "func1でセット"
def f1():
sampleMessage = "f1です!"
print("f1から見たsampleMessage:", sampleMessage)
def f2():
nonlocal sampleMessage
sampleMessage = "f2です!"
print("f2から見たsampleMessage:", sampleMessage)
def f3():
global sampleMessage
sampleMessage = "f3です"
print("f3から見たsampleMessage:", sampleMessage)
print("sampleMessage (1):", sampleMessage)
globalSampleMessageShow()
f1()
print()
print("sampleMessage (2):", sampleMessage)
globalSampleMessageShow()
f2()
print()
print("sampleMessage (3):", sampleMessage)
globalSampleMessageShow()
f3()
print()
print("sampleMessage (4):", sampleMessage)
func1()
print("func1実行終了:", sampleMessage)
"""
実行結果は、以下の通りです。
■スコープについて
sampleMessage (1): func1でセット
global sampleMessage: オッハー
f1から見たsampleMessage: f1です!
sampleMessage (2): func1でセット
global sampleMessage: オッハー
f2から見たsampleMessage: f2です!
sampleMessage (3): f2です!
global sampleMessage: オッハー
f3から見たsampleMessage: f3です
sampleMessage (4): f2です!
func1実行終了: f3です
"""
クラスの基本
クラス作成への第一歩、単純なクラスの記載方法です。
#クラスについて
print("■クラスについて")
"""
クラスであったとしても、メンバ変数を隠蔽するような仕組みは一切ない。
常にだれでもアクセスできる。
メンバ関数はクラス定義の内部に記載しているが、どこに書いてもよい。
メンバー関数は、常に(C++で言う)virtual修飾されていると考えてOK。
多重継承も許している。そして、これはvirtual継承と考えてOK(たぶん・・・)
pythonの慣習として、アンダースコア「_」で始まるメンバ関数、メンバ変数は外部からアクセスしない・・・というものがある。
(アクセスを禁じる仕組みがpythonに存在しないので、これは慣習として存在する)
"""
#クラスの定義
class Alctail:
# メンバ変数(初期値あり)。これはインスタンス事にメモリが確保される
_webSiteURL = "https://alctail.sakura.ne.jp/yht/";
#以下のような、リストや連想配列のようなmutableオブジェクトを初期値セットすると、Alctailのインスタンス間ですべて共有されてしまう。
#なので、変数宣言とインスタンスセットの記載はJavaのようにはできない。コンストラクタにてセットすべき。
#nameList = []
# コンストラクタ(ふつうの関数のように、引数も追加できる。第1引数のselfは必須)。これは1つしか定義できない様子。
def __init__(self, name):
print("Alctailの__init__(self)が呼ばれました")
self._itemList = [] # メンバ変数にインスタンスの割り当て
self._name = name
def getItemList(self):
return self._itemList
def getName(self):
return self._name
def getWebSiteUrl(self):
return self._webSiteURL
#クラスのインスタンス生成
inst1 = Alctail("aaaaaa")
inst2 = Alctail("bbbbbb")
inst1.getItemList().append("あああああ")
inst2.getItemList().append("いいいいい")
print(inst1.getItemList())
print(inst2.getItemList())
print(inst1.getWebSiteUrl())
print(inst2.getWebSiteUrl())
"""
実行結果は、以下の通りです。
■クラスについて
Alctailの__init__(self)が呼ばれました
Alctailの__init__(self)が呼ばれました
['あああああ']
['いいいいい']
https://alctail.sakura.ne.jp/yht/
https://alctail.sakura.ne.jp/yht/
"""
クラスの継承
多重継承のサンプルです。
#クラスの継承などについて
print("■クラスの継承")
"""
多重継承も可能。以下の場合、どういった呼ばれ方をするのか。
出力結果は以下の通り。
SampleBaseImplAの__init__が呼ばれました
SampleBaseImplBの__init__が呼ばれました
SampleBaseの__init__が呼ばれました
予測していた呼ばれ方と違うねぇ・・・(SampleBaseImplAの次にSampleBaseが呼ばれ、次にSampleBaseImplBかと思った)
これは同じクラスを複数探索しないようにする、「call-next-method」というメソッドの呼び出し順序解決の結果らしい(よく理解していないけど・・・)
なので、呼び出し順序が継承関係によって動的に変化する。
"""
class SampleBase:
def __init__(self, name):
print("SampleBaseの__init__が呼ばれました")
self.name = name
def getName(self):
return self.name;
class SampleBaseImplA(SampleBase):
def __init__(self, name):
print("SampleBaseImplAの__init__が呼ばれました")
super().__init__(name) # 親のコンストラクタの呼び出し
class SampleBaseImplB(SampleBase):
def __init__(self, name):
print("SampleBaseImplBの__init__が呼ばれました")
super().__init__(name) # 親のコンストラクタの呼び出し
#ひし形継承を行う(SampleBaseのインスタンスは1つしかできない。C++で言うと、pythonは常にvirtual継承となる)
class SampleBaseImplC(SampleBaseImplA, SampleBaseImplB):
def __init__(self, name):
# この時、これは誰のメソッドを指しているのか・・・?
super().__init__(name) # 親のコンストラクタの呼び出し
inst1 = SampleBaseImplC("その1")
print(inst1.getName())
"""
実行結果は、以下の通りです。
■クラスの継承
SampleBaseImplAの__init__が呼ばれました
SampleBaseImplBの__init__が呼ばれました
SampleBaseの__init__が呼ばれました
その1
"""
名前マングリングについて
継承した場合、メンバ変数・メンバ関数が、自分が作成しているものと、継承したクラスがもっているものとで、名前が被るケースがあります。
不意にかぶってしまった場合の、思ってもいない挙動をしてしまうのを防ぐための機構が名前マングリングです。
サンプルを以下に示します(サンプル内のコメントに詳細を記載しました)
#名前マングリングについて
print("■名前マングリングについて")
"""
pythonには「name mangling」(名前マングリング)という機能がある。
継承したときの不意の名前重複による事故を防ぐため・・・という目的で導入されている(それ以外の目的は無いので、それ以外の用途で使用しない)
以下のSampleAとSampleBでは、当初SampleAというクラスだけ存在し、使っていた。
しかし、新しい名前生成ロジックが誕生し、SampleBというクラスでオーバーライドした。
・・・通常は、これであまり困ることはない。
class SampleA:
def __init__(self):
print(self.createName())
def createName(self):
return "あいうえおです"
def getName(self):
return self.createName();
class SampleB(SampleA):
def createName(self):
return "かきくけこです"
inst1 = SampleB()
print(inst1.getName())
この実行結果は
かきくけこです
かきくけこです
となる(createNameの実装がSampleBのものが常に使われる)。
pythonは名前マングリングという機能があり、SampleAのコンストラクタ(__init__)の時点では、もともとのSampleAのメソッドのcreateNameが使いたい・・・という
ケースに対応してくれる(必要かどうかは別とする)
以下のソースの実行結果は(名前マングリングを使用)
あいうえおです
かきくけこです
・・・となる(__init__の中のcreateNameは、SampleAが持っているcreateNameになる)。
"""
class SampleA:
def __init__(self):
print(self.__createName())
def createName(self):
return "あいうえおです"
def getName(self):
return self.createName();
#ここがポイント
#先頭に二個以上の下線文字・・・の形式にすると名前マングリングの対象となる
#「__createName」は内部的には「_sampleA__createName」という変数名に置き換えられて、オーバーライドされるまえのcreateNameメソッドを保持している・・・らしい
__createName = createName
class SampleB(SampleA):
def createName(self):
return "かきくけこです"
inst1 = SampleB()
print(inst1.getName())
"""
実行結果を以下に示します。
■名前マングリングについて
あいうえおです
かきくけこです
"""
イテレーターとジェネレーター/ジェネレーター式
イテレーターについて、サンプルを示します。
イテレーターとの絡みで、ジェネレーター/ジェネレーター式についてサンプルを示します。
詳細はソースのコメントを参照。
#イテレーターについて
print("■イテレーターについて")
"""
for文などに渡しているイテレーターは簡単に自作できる。
__iter__メソッドを実装したクラスであり、かつ、戻り値は__next__メソッドを実装するクラス・・・、というだけ。
以下に例を示す
"""
class myIterator:
def __init__(self,data):
self.data = data;
self.index = 0
self.maxLen = len(data)
def __iter__(self):
return self;
def __next__(self):
if self.index >= self.maxLen:
# この例外を投げることで、データが終わったことを知らせる
raise StopIteration;
resultData = self.data[self.index];
self.index += 1
return resultData
iterData = myIterator("あいうえお")
for c in iterData:
print(c)
#ジェネレーターについて
print("■ジェネレーターについて")
"""
イテレーターを簡潔に作成するもの。
データを返すときに「yield文」を使うと、ジェネレーターになるとのこと。
わざわざ自分で、クラスを書いて、メンバ関数を実装して・・・といったことの必要がないのが利点。
"""
def sampleGenerator(data):
for index in range(len(data)):
yield data[index]
genData = ["あいうえお", "かきくけこ", "さしすせそ"]
for t in sampleGenerator(genData):
print("text : ", t)
#ジェネレーター式について
print("■ジェネレーター式について")
"""
関数の引数などで、ジェネレーターを1行で記載したい時・・・などに使用する。
リスト内砲表現は[]を使ったが、ジェネレーター式は()の中に記載する。
"""
# 0から10までの値を加算した値を生成する(addValueの値は55になる)
addValue = sum(i for i in range(11));
# 以下のように連想配列は、5個の要素を生成する
genArr = {x: x+1000 for x in range(5)}
#printの出力結果は「genArr : {0: 1000, 1: 1001, 2: 1002, 3: 1003, 4: 1004}」となる
print("genArr : ", genArr)
"""
実行結果は、以下の通りです。
■イテレーターについて
あ
い
う
え
お
■ジェネレーターについて
text : あいうえお
text : かきくけこ
text : さしすせそ
■ジェネレーター式について
genArr : {0: 1000, 1: 1001, 2: 1002, 3: 1003, 4: 1004}
"""
標準関数
pythonの標準関数において、いくつかのサンプルを以下に示します。
ファイル出力する処理もあるので、実行の際は気を付けてください。
#標準ライブラリ
print("■標準ライブラリの使い方サンプル")
print("・OSへのインターフェイス")
"""
OSのコマンドを実行することができます(C言語のsystem関数みたいなもの)
"""
import os #「from os import *」という記載はやめる。open関数の挙動が変わるらしい・・・
print("カレントディレクトリ:", os.getcwd())
#引数にコマンドプロンプトへのコマンドを渡せる。
#例として、以下で、メモ帳が起動する。
#os.system("notepad")
print("・ファイルのコピーや移動の操作")
"""
便利な関数がshutilに定義されている。
"""
import shutil
#以下で、第一引数で指定したファイルを、第二引数で指定したパスにファイルコピーする
shutil.copyfile("d:/alctail_tmp114514.txt", "d:/alctail_tmp114514_copy.txt")
#以下で、第一引数で指定したファイルを、第二引数で指定したパスに移動する
shutil.move("d:/alctail_tmp114514_copy.txt", "d:/alctail_tmp114514_copy_move.txt")
print("・ファイルのワイルドカード表記")
"""
以下で指定したディレクトリ内にあるファイルの一覧をリストで取得できる
"""
import glob
fileList = glob.glob("d:/*")
print("・正規表現によるマッチングと置換")
"""
正規表現を使ったマッチング処理や置換もあります。簡単な例を示します。
"""
import re
matchList = re.findall(r"k[a-z]*", "a i u e o ka ki ku ke ko sa si su se so")
replaceResult = "これもうわかんねぇな".replace("ぇ", "ぇぇぇぇぇ")
print("・平均、中央値、分散を計算する")
numList = [0, 10, 2, 3, 4, 5, 6, 7, 8, 90]
import statistics
numListMean = statistics.mean(numList)
numListMedian = statistics.median(numList)
numListVariance = statistics.variance(numList)
print("平均:", numListMean)
print("中央値:", numListMedian)
print("分散:", numListVariance)
print("・日付")
from datetime import date
nowTime = date.today()
print(nowTime.strftime("%m-%d-%y. %d %b %Y is a %A on the %d day of %B."))
print("・出力のフォーマット")
"""
構造が複雑な連想配列などを、インデントを自動でつけて見やすくしてくれるモジュールがあります
以下のマップを
{'author': '兄貴スレの人々',
'detail': {'head1': 'だらしねぇという 戒めの心', 'head2': '歪みねぇという 賛美の心', 'head3': '仕方ないという 許容の心'},
'relation': ['森の妖精', '妖精哲学', 'カズヤの教え'],
'title': '妖精哲学の三信について'}
・・・といった感じに出力してくれます。
"""
sampleMap = {
"title": "妖精哲学の三信について",
"author": "兄貴スレの人々",
"detail":{
"head1": "だらしねぇという 戒めの心",
"head2": "歪みねぇという 賛美の心",
"head3": "仕方ないという 許容の心"
},
"relation":["森の妖精", "妖精哲学", "カズヤの教え"]
}
import pprint
pprint.pprint(sampleMap, width=100)
print("・文字列テンプレート")
"""
文字列中に、プレースホルダを記載して、それに対し置き換えた対象の文字列をセットし、文字列を生成することができます。
プレースホルダは文字列の前後に半角スペースをいれて$nameと記載します。
${data}と記載すると、前後のスペースは不要になります。
「$」自体を出力させたい場合は「$$」と記載すればOKです。
"""
from string import Template
templateText = Template("${data1}abcdef $data2 ghijk")
templateResult = templateText.substitute(data1="お湯ください", data2="お湯")
print("templateResult : ", templateResult)
print("・ログ記録")
"""
デフォルトでは標準エラー出力にセットした文字列が出力される。
ここでは、loggerを自分で作成し、ファイルにログ出力する例を示す。
"""
import logging
myLogger = logging.getLogger("aiueoLogger")
myLogger.setLevel(logging.DEBUG)
#ファイルに出力するためのhandlerを作成しセットする
myLoggerFileHandler = logging.FileHandler(filename="d:/aiueo.log")
myLoggerFileHandler.setLevel(logging.DEBUG)
myLoggerFileHandler.setFormatter(logging.Formatter("%(asctime)s [%(levelname)s] : %(message)s"))
myLogger.addHandler(myLoggerFileHandler)
#おまけにコンソールにもログメッセージを出すようにする
myLoggerCosoleHandler = logging.StreamHandler();
myLoggerCosoleHandler.setLevel(logging.DEBUG)
myLoggerCosoleHandler.setFormatter(logging.Formatter("%(asctime)s [%(levelname)s] : %(message)s"))
myLogger.addHandler(myLoggerCosoleHandler)
myLogger.debug("debugログのメッセージです")
myLogger.info("infoログのメッセージです")
myLogger.warning("warnログのメッセージです")
myLogger.error("errorログのメッセージです")
print("・弱参照")
"""
参照はしていても、ガベージコレクションの処理に対し、参照関係はない扱いにしてもらうための機構です。
"""
import weakref, gc
#なにか適当にデータを作る
class weakSampleClass:
def __init__(self, value):
self.value = value
def __repr__(self):
return str(self.value)
weakSampleData = weakSampleClass("あいうえお")
#弱参照を行うオブジェクトを作成する
weakRefObj = weakref.WeakValueDictionary()
weakRefObj["aiueo"] = weakSampleData #データへの参照をセットする
del weakSampleData # データが不要になったので削除する
gc.collect() # 不要メモリを回収させる(sampleDataListが回収される・・・はず)
#弱参照にセットした先のデータが消えているか確認
if 'aiueo' in weakRefObj:
print("weakRefObjに要素がありました")
else:
print("weakRefObjに要素はありませんでした")
print("・10進浮動小数演算について")
"""
Javaで言うBigDecimalのようなことができる
"""
from decimal import Decimal
decimalNum1 = Decimal("0.1")
decimalNum2 = Decimal("0.1")
decimalNumCalcResult = decimalNum1 + decimalNum2
print("decimalNumCalcResult : ", decimalNumCalcResult)
"""
実行結果は、以下の通りです。
■標準ライブラリの使い方サンプル
・OSへのインターフェイス
カレントディレクトリ: D:\repository\eclipse\python\study\python\study1\Study1
・ファイルのコピーや移動の操作
・ファイルのワイルドカード表記
・正規表現によるマッチングと置換
・平均、中央値、分散を計算する
平均: 13.5
中央値: 5.5
分散: 731.1666666666666
・日付
02-24-19. 24 Feb 2019 is a Sunday on the 24 day of February.
・出力のフォーマット
{'author': '兄貴スレの人々',
'detail': {'head1': 'だらしねぇという 戒めの心', 'head2': '歪みねぇという 賛美の心', 'head3': '仕方ないという 許容の心'},
'relation': ['森の妖精', '妖精哲学', 'カズヤの教え'],
'title': '妖精哲学の三信について'}
・文字列テンプレート
templateResult : お湯くださいabcdef お湯 ghijk
・ログ記録
2019-02-24 13:12:17,769 [DEBUG] : debugログのメッセージです
2019-02-24 13:12:17,789 [INFO] : infoログのメッセージです
2019-02-24 13:12:17,789 [WARNING] : warnログのメッセージです
2019-02-24 13:12:17,789 [ERROR] : errorログのメッセージです
・弱参照
weakRefObjに要素はありませんでした
・10進浮動小数演算について
decimalNumCalcResult : 0.2
"""